virtualbox 錯誤處理
sudo apt-get install dkms
sudo apt-get install linux-headers-`uname -r` build-essential
sudo /etc/init.d/vboxdrv setup
2011年4月1日 星期五
linux與 virtualbox上的xp 建立共用資料夾
環境:本機:ubuntu 10.04
virtualbox :掛載windows xp
目的:建立共用資料夾
step1: 再ubuntu建立一個資料夾
 step2: 再virtualbox右下方 右鍵點選資料夾的圖示 進行設定
step2: 再virtualbox右下方 右鍵點選資料夾的圖示 進行設定



 step3: 在xp上開啟我的電腦 點選工具列中-> 連線網路硬碟機
step3: 在xp上開啟我的電腦 點選工具列中-> 連線網路硬碟機



virtualbox :掛載windows xp
目的:建立共用資料夾
step1: 再ubuntu建立一個資料夾


選擇在ubuntu上共用資料夾的路徑&並建立在xp上所見的資料夾名稱(隨便取)

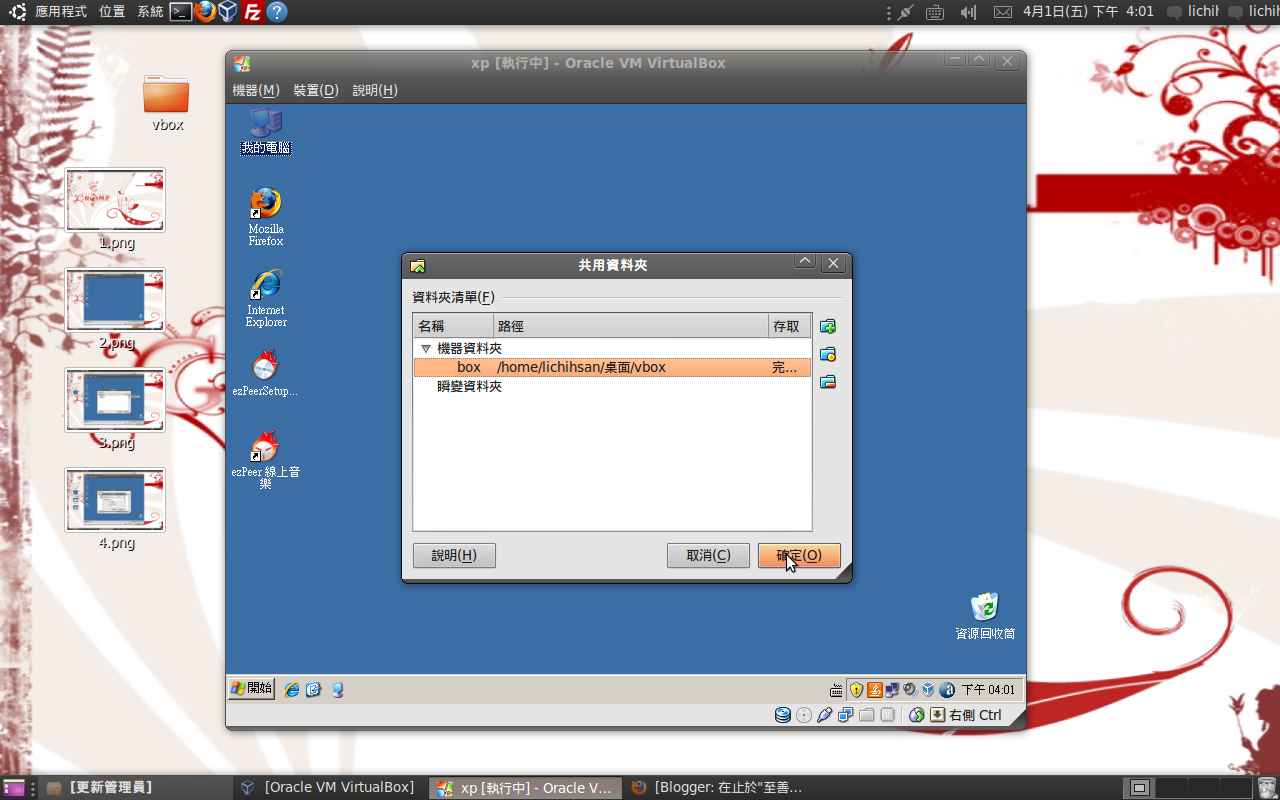


輸入 \\Vboxsvr\box

完成

2011年3月23日 星期三
hadoop 多機安裝
環境:10台 ubuntu 10.04
hostname
node1 namenode & jobtracker & datanode & tasktracker
node2 datanode & tasktracker
node3 datanode & tasktracker
node4 datanode & tasktracker
node5 datanode & tasktracker
node6 datanode & tasktracker
node7 datanode & tasktracker
node8 datanode & tasktracker
node9 datanode & tasktracker
node10 datanode & tasktracker
step0: node1~node10 再第二裝網卡設定ip
step1: 設定兩台機器ssh登入免密碼 (再node1做)
hostname
node1 namenode & jobtracker & datanode & tasktracker
node2 datanode & tasktracker
node3 datanode & tasktracker
node4 datanode & tasktracker
node5 datanode & tasktracker
node6 datanode & tasktracker
node7 datanode & tasktracker
node8 datanode & tasktracker
node9 datanode & tasktracker
node10 datanode & tasktracker
每一台 創建 username(hadooper) userpasswd(*****) usergroup(hadooper)
並把改使用者設定為具有車籍使用者的權限 =>sudo adduser username admin
step0: node1~node10 再第二裝網卡設定ip
step1: 設定兩台機器ssh登入免密碼 (再node1做)
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P "" cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys scp -r ~/.ssh node2:~/(在node1做 複製到 node2~node10)step2:安裝java(node1~node10) sudo apt-get purge java-gcj-compat
sudo add-apt-repository "deb http://archive.canonical.com/ lucid partner" sudo apt-get update sudo apt-get install sun-java6-jdk sun-java6-plugin sudo update-java-alternatives -s java-6-sun
step3:下載安裝Hadoop~$ cd /opt
/opt$ sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz /opt$ sudo tar zxvf hadoop-0.20.2.tar.gz /opt$ sudo mv hadoop-0.20.2/ hadoop /opt$ sudo chown -R 使用者帳號:使用者群組 hadoop /opt$ sudo mkdir /var/hadoop /opt$ sudo chown -R 使用者帳號:使用者群組 /var/hadoop
step4: 設定 hadoop-env.sh
/opt$ cd hadoop/ /opt/hadoop$ gedit conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-6-sun export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=/opt/hadoop/conf export HADOOP_LOG_DIR=/tmp/hadoop/logs export HADOOP_PID_DIR=/tmp/hadoop/pids
step5: 設定 hadoop-site.xml
/opt/hadoop# gedit conf/core-site.xml <configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/hadoop-${user.name}</value>
</property>
</configuration> /opt/hadoop# gedit conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration> /opt/hadoop# gedit conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>node1:9001</value>
</property>
</configuration> step6: 設定masters及slaves
/opt/hadoop$ gedit conf/slavesstep7: 將第一台設定的資料copy到另外幾台
ssh node2~node10
/opt/hadoop$ "sudo mkdir /opt/hadoop" /opt/hadoop$ "sudo chown -R 使用者帳號:使用者群組 /opt/hadoop" /opt/hadoop$ "sudo mkdir /var/hadoop" /opt/hadoop$ "sudo chown -R 使用者帳號:使用者群組 /var/hadoop"
/opt/hadoop$ scp -r /opt/hadoop/* node2:/opt/hadoop/
step8: 格式化HDFS
/opt/hadoop$ bin/hadoop namenode -format step9: 啟動Hadoop(在node1上執行)
/opt/hadoop$ bin/start-dfs.sh
/opt/hadoop$ /opt/hadoop/bin/start-mapred.sh
hadoop 單機安裝
環境:Linux ubuntu 10.04
安裝前先作一些設定
1.登入資訊(使用者:使用者群組:使用者密碼)
2.讓該使用者具有root權限=> sudo adduser 使用者帳號 admin
開始安裝:
step1: 設定ssh登入機器免密碼的設定
安裝前先作一些設定
1.登入資訊(使用者:使用者群組:使用者密碼)
2.讓該使用者具有root權限=> sudo adduser 使用者帳號 admin
開始安裝:
step1: 設定ssh登入機器免密碼的設定
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P "" cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys step2: 安裝java
sudo apt-get purge java-gcj-compat sudo add-apt-repository "deb http://archive.canonical.com/ lucid partner" sudo apt-get update sudo apt-get install sun-java6-jdk sun-java6-plugin sudo update-java-alternatives -s java-6-sun step3: 下載安裝hadoop
cd /opt /opt$ sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/core/hadoop-0.20.2
/hadoop-0.20.2.tar.gz /opt$ sudo tar zxvf hadoop-0.20.2.tar.gz /opt$ sudo mv hadoop-0.20.2/ hadoop /opt$ sudo chown -R 使用者帳號:使用者密碼 hadoop /opt$ sudo mkdir /var/hadoop /opt$ sudo chown -R 使用者帳號:使用者密碼 /var/hadoop
step4: 設定 hadoop-env.sh 貼入以下資訊
指令: cat >> conf/hadoop-env.sh << EOF
export JAVA_HOME=/usr/lib/jvm/java-6-sun
export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=/opt/hadoop/conf
step5: 設定 core-site.xml, hdfs-site.xml, mapred-site.xml
core-site.xml /設定datanod&namenode
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/hadoop-\${user.name}</value>
</property>
</configuration>
hdfs-site.xml //設定備份數<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> </property> </configuration>
mapred-site.xml //設定 jobtracker &tasktracker
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
step6:格式化
/opt/hadoop$ bin/hadoop namenode -format step7: 啟動Hadoop
/opt/hadoop$ bin/start-all.sh
測試1.http://localhost:50030 管理介面2.http://localhost:50060 Hadoop Task Tracker 狀態
3.http://localhost:50070 hadoop dfs狀態
2011年3月15日 星期二
在linux上複製virtualbox vdi
前言:
當使用virtualbox 安裝好作業系統(ubunntu,xp,win7....etc )之後,之後如果還需在virtualbox重灌相同系統時或者同一個virtualbox要安裝多個虛擬機器,可以使用vdi複製的的指令產生vdi檔,直接在virtualbox掛載即可,節省時間
要注意的是 很多人可能會認為說在linux上 複製直接使用cp指令就可以了壓!這是錯的
因為virtualbox上每個vdi檔有唯一的UUID如果使用cp指令會產生錯誤,必須使用
VBoxManage clonevdi old.vdi new.vdi (要加上vdi檔的路徑)
以下為教學:
step1:
使用virtualbox安裝作業系統,安裝完成之後就會產生一個vdi檔(預設是放在~/.Virtualbox),這部份網路上有很多教學 就不在此多加教學了
step2:
下複製指令(如下圖)
 step3:
step3:
開啟virtualbox 掛載 vdi







完成 如有問題歡迎指教
當使用virtualbox 安裝好作業系統(ubunntu,xp,win7....etc )之後,之後如果還需在virtualbox重灌相同系統時或者同一個virtualbox要安裝多個虛擬機器,可以使用vdi複製的的指令產生vdi檔,直接在virtualbox掛載即可,節省時間
要注意的是 很多人可能會認為說在linux上 複製直接使用cp指令就可以了壓!這是錯的
因為virtualbox上每個vdi檔有唯一的UUID如果使用cp指令會產生錯誤,必須使用
VBoxManage clonevdi old.vdi new.vdi (要加上vdi檔的路徑)
以下為教學:
step1:
使用virtualbox安裝作業系統,安裝完成之後就會產生一個vdi檔(預設是放在~/.Virtualbox),這部份網路上有很多教學 就不在此多加教學了
step2:
下複製指令(如下圖)

開啟virtualbox 掛載 vdi







完成 如有問題歡迎指教
訂閱:
文章 (Atom)